
這節要描述 Model.Compiler 主要的運作過程。
範例程式:
from tensorflow.keras.models import Sequential
from tensorflow.keras import layers
#建構模型
model = Sequential([
layers.Dense(512, activation="relu")
])
#編譯模型
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
model.build(input_shape=(None, 784))
keras.engine.sequential 類別繼承父類別 keras.engine.training.Model,而compiler函式被此父類別實作。函式對 keras.engine.sequential.Sequential 物件 (model) 做一些檢查、設定。
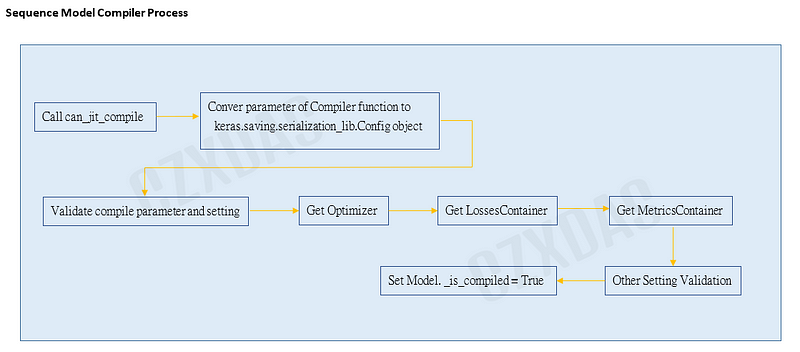
因為涉及Tensorflow底層,這邊"大致"上觀察compile 會作:
(1)
執行 can_jit_compile函式:
函式主要說明為 "Returns True if TensorFlow XLA is available for the platform." ,
為檢查作業系統、處理器種類來決定是否支援 XLA (https://www.tensorflow.org/xla)。
如果參數jit_compile有設定True,但作業系統與處理器不支援(如Apple ARM),或 GPU為可插拔設備,將停止jit_compile。
(2)
keras.engine.sequential.Sequential._compile_config 會被指派物件為keras.saving.serialization_lib.Config 物件,基本上就是將參數包在此物件內。
(3)
with self.distribute_strategy.scope()
此步驟後,會與TensorFlow分佈式訓練有關。詳細可參考
https://www.tensorflow.org/guide/distributed_training
如果沒有指定,會用預設默認的DefaultDistributionStrategy
tf.distribute.get_strategy() => tensorflow.python.distribute.distribute_lib._DefaultDistributionStrategy
所以with self.distribute_strategy.scope()
指示Keras使用哪種策略來分佈訓練,通過在此作用域內創建模型、優化器。
(4)
_validate_compile(optimizer, metrics, **kwargs)
檢查參數是否合法支援。如 tf.compat.v1.keras.Optimizer的最佳化實體、參數distribute、參數target_tensors 與 排除sample_weight_mode之外的其它參數存在,都會引發例外錯誤。
(5)
keras.engine.sequential.Sequential.optimizer = self._get_optimizer(optimizer)
非常重要的一段程式。
這邊會去keras.optimizers.get 函示依照傳入的identifier來取回optimizer物件。而依範例傳入的identifier為"rmsprop"字串。
大致上如果不是MAC系統,會以下列模組找出對應的最佳化模組類別:
"adadelta": keras.optimizers.adadelta.Adadelta
"adagrad": 'keras.optimizers.adagrad.Adagrad
"adam": 'keras.optimizers.adam.Adam
"adamax": keras.optimizers.adamax.Adamax
"experimentaladadelta": keras.optimizers.adadelta.Adadelta
"experimentaladagrad": keras.optimizers.adagrad.Adagrad
"experimentaladam": keras.optimizers.adam.Adam
"experimentalsgd": keras.optimizers.sgd.SGD
"nadam": keras.optimizers.nadam.Nadam
"rmsprop": keras.optimizers.rmsprop.RMSprop
"sgd": keras.optimizers.sgd.SGD
"ftrl": keras.optimizers.Ftrl
"lossscaleoptimizer": keras.mixed_precision.loss_scale_optimizer.LossScaleOptimizerV3
"lossscaleoptimizerv3": keras.mixed_precision.loss_scale_optimizer.LossScaleOptimizerV3
"lossscaleoptimizerv1":
keras.mixed_precision. loss_scale_optimizer.LossScaleOptimizer
如果是MAC系統則是會以下列模組類別找對應最佳化器(與上列多少有些差異):
"adadelta": keras.optimizers.legacy.adagrad.adadelta_legacy.Adadelta
"adagrad": keras.optimizers.legacy.adagrad.adagrad_legacy.Adagrad
"adam": keras.optimizers.legacy.adam.adam_legacy.Adam,
"adamax": keras.optimizers.legacy.adamax.Adamax
"experimentaladadelta": keras.optimizers.adadelta.Adadelta
"experimentaladagrad": keras.optimizers.adagrad.Adagrad
"experimentaladam": keras.optimizers.adam.Adam
"experimentalsgd": keras.optimizers.sgd.SGD
"nadam": keras.optimizers.legacy.nadam.Nadam
"rmsprop": keras.optimizers.legacy.rmsprop.RMSprop
"sgd": keras.optimizers.legacy.gradient_descent.SGD
"ftrl": keras.optimizers.legacy.ftrl.Ftrl
"lossscaleoptimizer": keras.mixed_precision.loss_scale_optimizer.LossScaleOptimizer
"lossscaleoptimizerv3": keras.mixed_precision.loss_scale_optimizer.LossScaleOptimizerV3
"lossscaleoptimizerv1": keras.mixed_precision.loss_scale_optimizer.LossScaleOptimizer
找到對應模組類別後,最後透過 keras.saving.legacy.serialization.deserialize_keras_object 反序列化參數設定形成optimizer模組物件。
(6)
keras.engine.sequential.Sequential.compiled_loss 設定為 compile_utils.LossesContainer物件。
如果參數loss傳入的物件不是繼承 keras.engine.compile_utils.LossesContainer 的實體(父類別為keras.engine.compile_utils.Container),則透過
keras.engine.compile_utils.LossesContainer類別產生loss物件。
LossesContainer類別如下: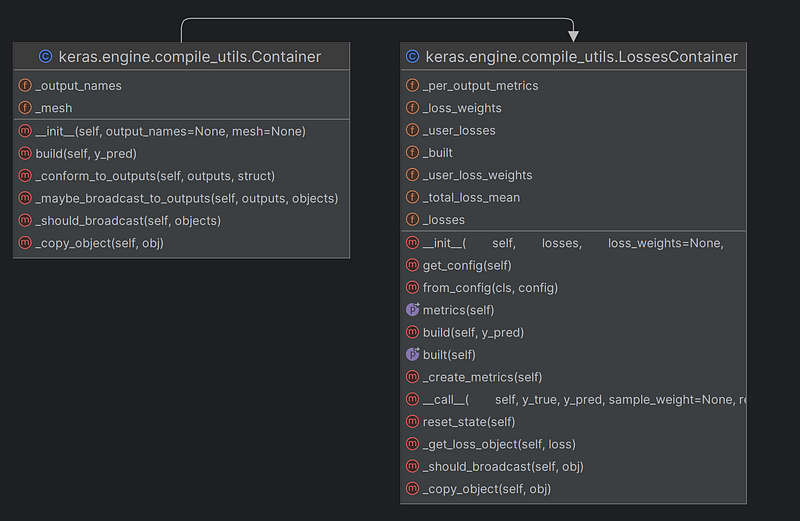
(7)
self.compiled_metrics 設定為 compile_utils.MetricsContainer物件。
傳入的metrics list使用keras.engine.compile_utils.MetricsContainer(父類別為keras.engine.compile_utils.Container)包成類別物件,其中會檢查是否有重複名稱,有則產生例外錯誤。
MetricsContainer類別如下: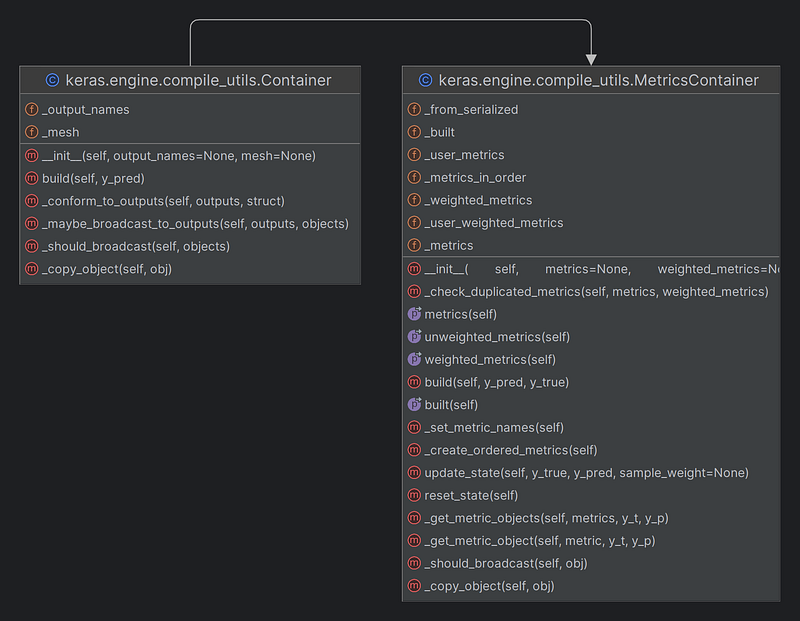
(8)
檢查 run_eagerly and jit_compile flag變數是否同時被啟用,如果是則產生例外錯誤。
(9)
最後會將自身instance的 _is_compiled 變數設定為 True,代表有成功compiler model。
以上大致上是compiler會做主要的事項,這邊如果沒有成功,不能做後續的訓練。所以這步驟也是必須執行的步驟。
稍作紀錄於此。


 iThome鐵人賽
iThome鐵人賽